
Disclaimer
This training and inference pipeline was developed by NVIDIA. It is based on a segmentation and classification model developed by NVIDIA researchers in conjunction with the NIH. The Software is for Research Use Only. Software’s recommendation should not be solely or primarily relied upon to diagnose or treat COVID-19 by a Healthcare Professional. This research use only software has not been cleared or approved by FDA or any regulatory agency.
Model Overview
The model described in this card is used to segment the lung region from the 3D chest CT images.
Model Architecture
The model is a deep neural network with 3D anisotropic hybrid network [2].
Training Algorithm
This model is developed by NVIDIA researchers in conjunction with the NIH. The segmentation of lung region is formulated as the voxel-wise binary classification. Each voxel is predicted as either foreground (lung) or background. And the model is optimized with gradient descent method minimizing soft dice loss [3] between the predicted mask and ground truth segmentation. The model is trained using four 16GB NVIDIA Tesla V100 GPUs, and its pipeline is developed with NVIDIA Clara Train.
Intended Use
Primary use case intended for this model is lung segmentation for CT images with certain disease-related patterns. The model is for research purposes only.
Input
3D CT volume with intensity in HU. Within the Clara Train pipeline for both training and inference, the images are preprocessed by “pre-transforms” [1] so that: 1) images are resampled to a resolution of 0.8x0.8x5 mm and 2) intensity is clipped to [-1500, 500] HU. For output, the mask predictions are resampled back to original resolution using “post-transform” [1]. The actual input of the model is a cropped region-of-interest (ROI) with fixed size 224x224x32. The patches sampled from the CT volumes are fed into the network for training, and the sliding-window scheme is utilized to achieve segmentation of the entire CT at inference.
Output
Binary mask of the lung region in the input image.
How to use this model
This model needs to be used with NVIDIA hardware and software. For hardware, the model can run on any NVIDIA GPU with memory greater than 12 GB. For software, this model can be used with NVIDIA Clara Train.
Example
Input Image
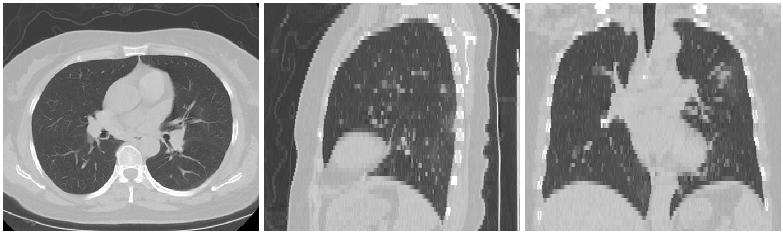
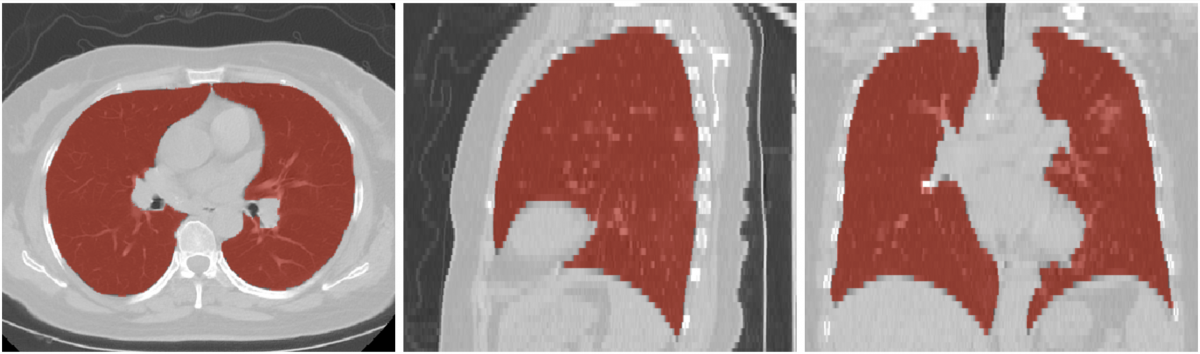
Output Image

Output Image Overlaid on Input Image
Training / Validation Data
This model was trained on a global dataset with a large experimental cohort collected from across the globe. The CT volumes of 95 independent subjects with experts’ lung region annotation were used as training and validation sets.
Performance KPI
Dice score is used for evaluating the performance of the model. On the validation set, the trained model achieved 95% on average (range 0.85-0.99, stdev 0.06).
Limitations
Disease Related Patterns
The model is trained specifically for addressing GGO/consolidation patterns, thus may not universally cover all conditions, or work ideally for other types of disease patterns.
License
End User License Agreement is included with the product. Licenses are also available along with the model application zip file. By pulling and using the Clara Train SDK container and downloading models, you accept the terms and conditions of these licenses.
References
[1] https://developer.nvidia.com/clara-medical-imaging
[2] Liu, S., Xu, D., Zhou, S.K., Pauly, O., Grbic, S., Mertelmeier, T., Wicklein, J., Jerebko, A., Cai, W. and Comaniciu, D., 2018, September. 3d anisotropic hybrid network: Transferring convolutional features from 2d images to 3d anisotropic volumes. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 851-858). Springer, Cham. https://arxiv.org/pdf/1711.08580.pdf
[3] Milletari, F., Navab, N. and Ahmadi, S.A., 2016, October. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In 2016 Fourth International Conference on 3D Vision (3DV) (pp. 565-571). IEEE.